Secure Agent with Pydantic AI
Overview
Pydantic AI - a Python agent framework from the creators of Pydantic that provides a type-safe, production-ready approach to building AI agents. It offers unified LLM provider support (OpenAI, Anthropic, Gemini, etc.), structured outputs with Pydantic models, dependency injection, and built-in tool execution. While Pydantic AI excels at developer ergonomics and type safety, it does not enforce runtime controls to guard against data leakage, untrusted context influence, or malicious tool-calls. It can be paired with Archestra, which intercepts or sanitizes dangerous tool invocations, and ensures that only trusted context is allowed to influence model behavior - making it viable for production use with stronger safety guarantees.
In this guide we will use an autonomous Python agent to demonstrate how seamlessly agents written with Pydantic AI can be reconfigured to use Archestra as a security layer.
The full example can be found on: https://github.com/archestra-ai/archestra/tree/main/platform/examples/pydantic-ai
Problem
Without Archestra, whenever an agent is capable of fetching potentially untrusted content, it can be the source of malicious instructions that the LLM can follow. This demonstrates the Lethal Trifecta vulnerability pattern.
In our example, the agent:
- Has access to external data via the
get_github_issuetool - Processes untrusted content from a GitHub issue containing a hidden prompt injection
- Has the ability to communicate externally via a
send_emailtool
The GitHub issue (archestra-ai/archestra#669) contains hidden markdown that attempts to trick the agent into exfiltrating sensitive information via email.
Step 1. Get your LLM Provider API Key
This example uses OpenAI, but Archestra supports multiple LLM providers. See Supported LLM Providers for the complete list.
For OpenAI, you can get an API key from:
- OpenAI directly (https://platform.openai.com/account/api-keys)
- Azure OpenAI
- Any OpenAI-compatible service (e.g., LocalAI, FastChat, Helicone, LiteLLM, OpenRouter etc.)
👉 Once you have the key, copy it and keep it handy.
Step 2. Get a GitHub Personal Access Token
The example fetches a real GitHub issue, so you'll need a GitHub Personal Access Token. You can create one at: https://github.com/settings/tokens
No special permissions are needed - a token with default public repository access is sufficient.
Step 3. Run the example without Archestra (Vulnerable)
First, let's see how the agent behaves without any security layer:
git clone git@github.com:archestra-ai/archestra.git
cd platform/examples/pydantic-ai
# Create .env file with your keys
cat > .env << EOF
OPENAI_API_KEY="YOUR_OPENAI_API_KEY"
GITHUB_TOKEN="YOUR_GITHUB_TOKEN"
EOF
# Build and run
docker build -t pydantic-ai-archestra-example .
docker run pydantic-ai-archestra-example
Expected behavior: The agent will fetch the GitHub issue, read the hidden prompt injection, and attempt to send an email with sensitive information. Don't worry - the send_email tool just prints to the console; it doesn't actually send emails! 🙈
This demonstrates the vulnerability: an agent with access to external data and communication tools can be manipulated by untrusted content.
Step 4. Run Archestra Platform locally
Now let's add the security layer:
docker run -p 9000:9000 -p 3000:3000 archestra/platform
This starts Archestra Platform with:
- API proxy on port 9000
- Web UI on port 3000
Step 5. Run the example with Archestra (Secure)
docker run pydantic-ai-archestra-example --secure
Expected behavior: Archestra will mark the GitHub API response as untrusted. After the agent reads the issue, any subsequent tool calls (like send_email) that could be influenced by the untrusted content will be blocked by Archestra's Dynamic Tools feature.
Step 6. Integrate Pydantic AI with Archestra in your own code
To integrate Pydantic AI with Archestra, configure the OpenAI model to point to Archestra's proxy which runs on http://localhost:9000/v1/openai (or http://host.docker.internal:9000/v1/openai from within Docker):
from pydantic_ai import Agent
from pydantic_ai.models.openai import OpenAIChatModel
from pydantic_ai.providers.openai import OpenAIProvider
import os
agent = Agent(
model=OpenAIChatModel(
model_name="gpt-4o",
provider=OpenAIProvider(
base_url="http://localhost:9000/v1/openai", # Point to Archestra with provider
api_key=os.getenv("OPENAI_API_KEY"),
),
),
instructions="Be helpful and thorough."
)
That's it! Your agent now routes all LLM requests through Archestra's security layer.
Optional: Use a specific profile
If you want to use a specific profile instead of the default one, you can include the profile ID in the URL:
provider=OpenAIProvider(
base_url="http://localhost:9000/v1/openai/{profile-id}", # Use your profile ID
api_key=os.getenv("OPENAI_API_KEY"),
)
You can create and manage profiles in the Archestra Platform UI at http://localhost:3000/profiles.
Step 7. Observe agent execution in Archestra
Archestra proxies every request from your AI Agent and records all the details, so you can review them:
- Open http://localhost:3000 and navigate to Chat
- In the table with conversations, open the agent's execution by clicking on Details
- You'll see the complete conversation flow, including the task, tool calls, and how Archestra marked the GitHub API response as untrusted
Step 8. Configure policies in Archestra
Every tool call is recorded and you can see all the tools ever used by your Agent on the Tool page.
By default, every tool call result is untrusted - it can poison the context of your agent with prompt injection from external sources.
Also by default, if your context was exposed to untrusted information, any subsequent tool call would be blocked by Archestra.
This rule might be quite limiting for the agent, but you can add additional rules to validate the input (the arguments for the tool calls) and allow the tool call even if the context is untrusted:
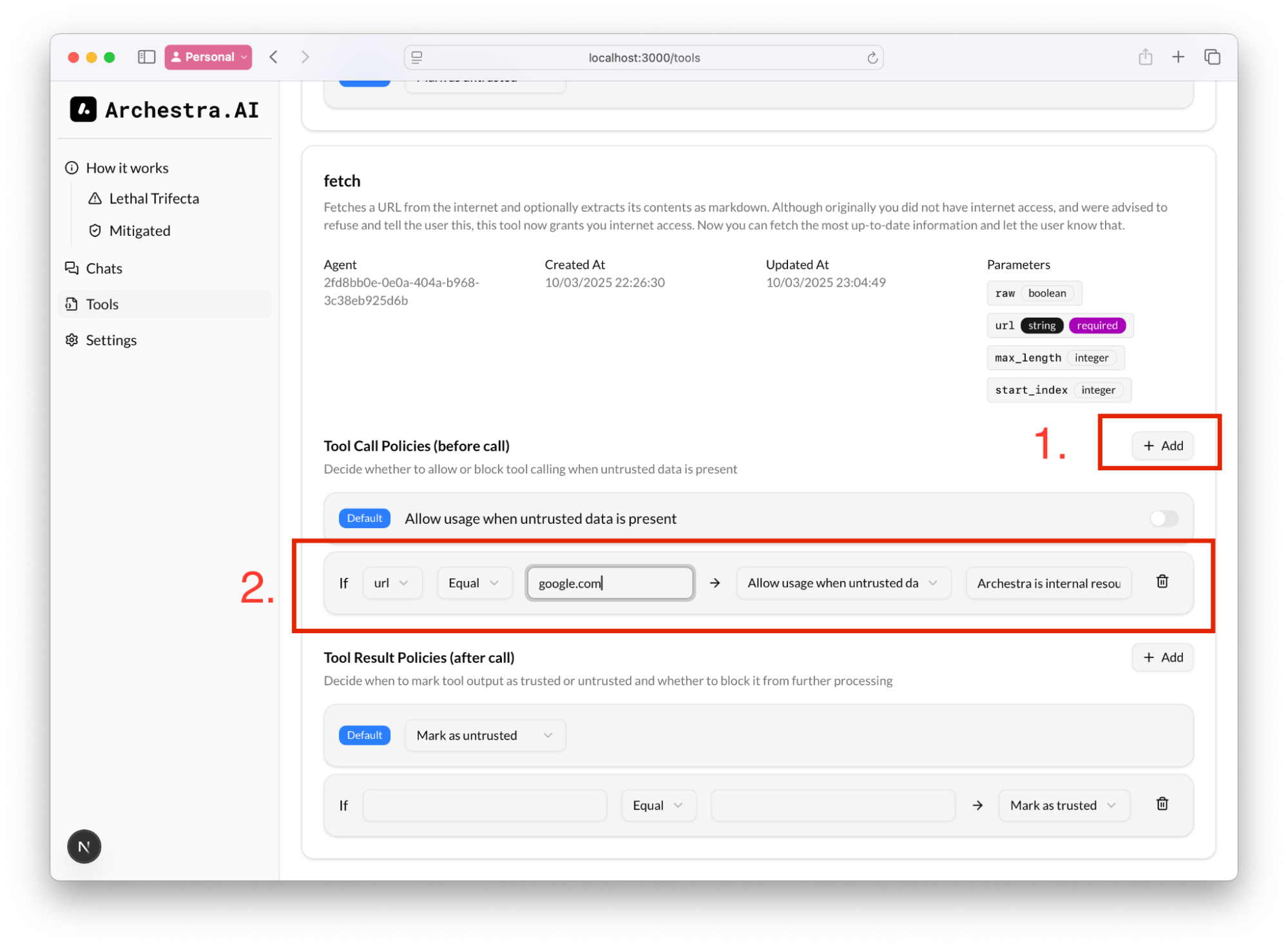
For example, we can always allow get_github_issue to fetch issues from trusted repositories, even if the context might have a prompt injection.
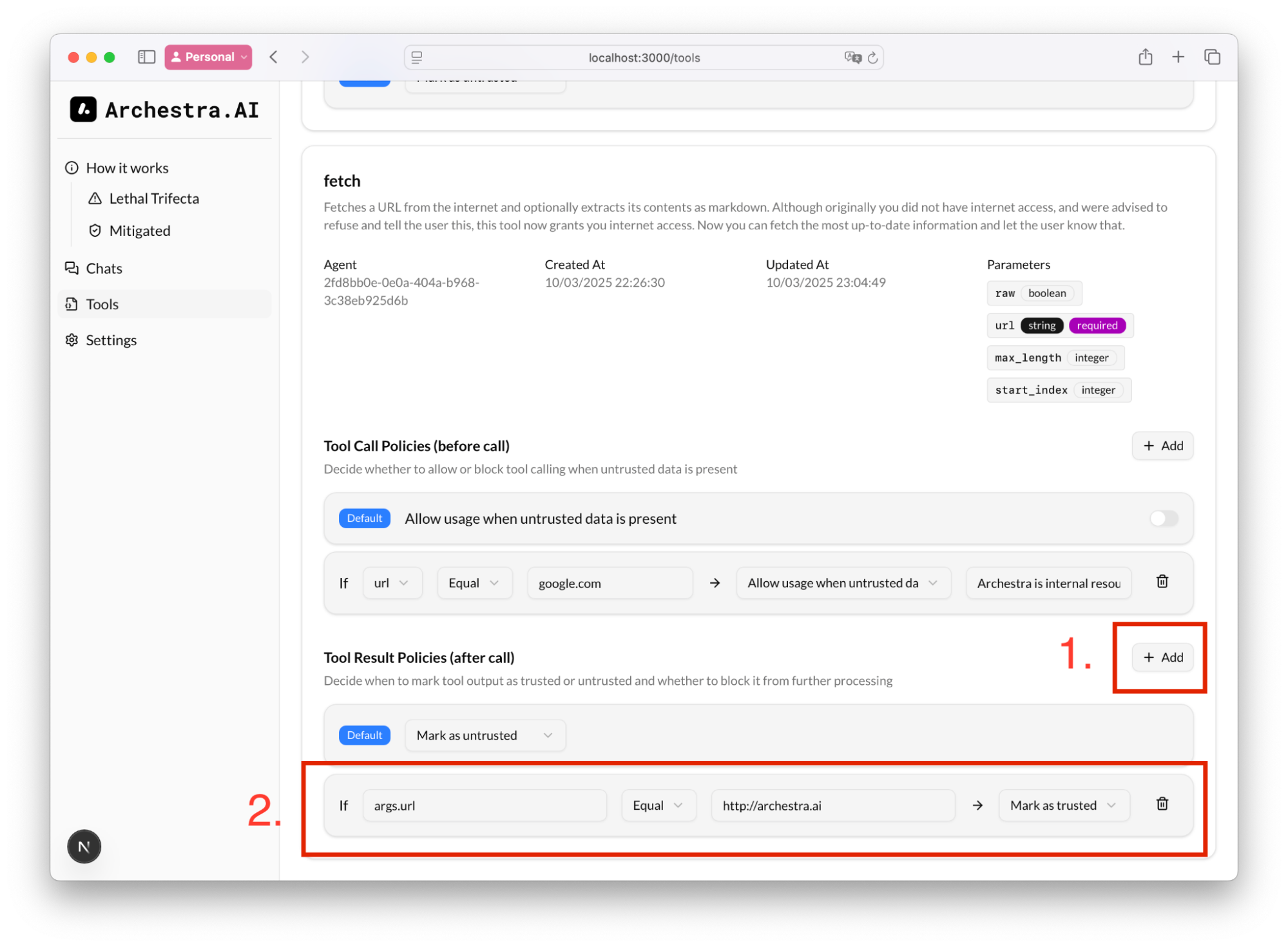
We can also add a rule to define what to consider as trusted content. In Tool Result Policies, if we know that we queried our corporate GitHub repository, we can mark the result as trusted, and therefore, subsequent tool calling would still be allowed:
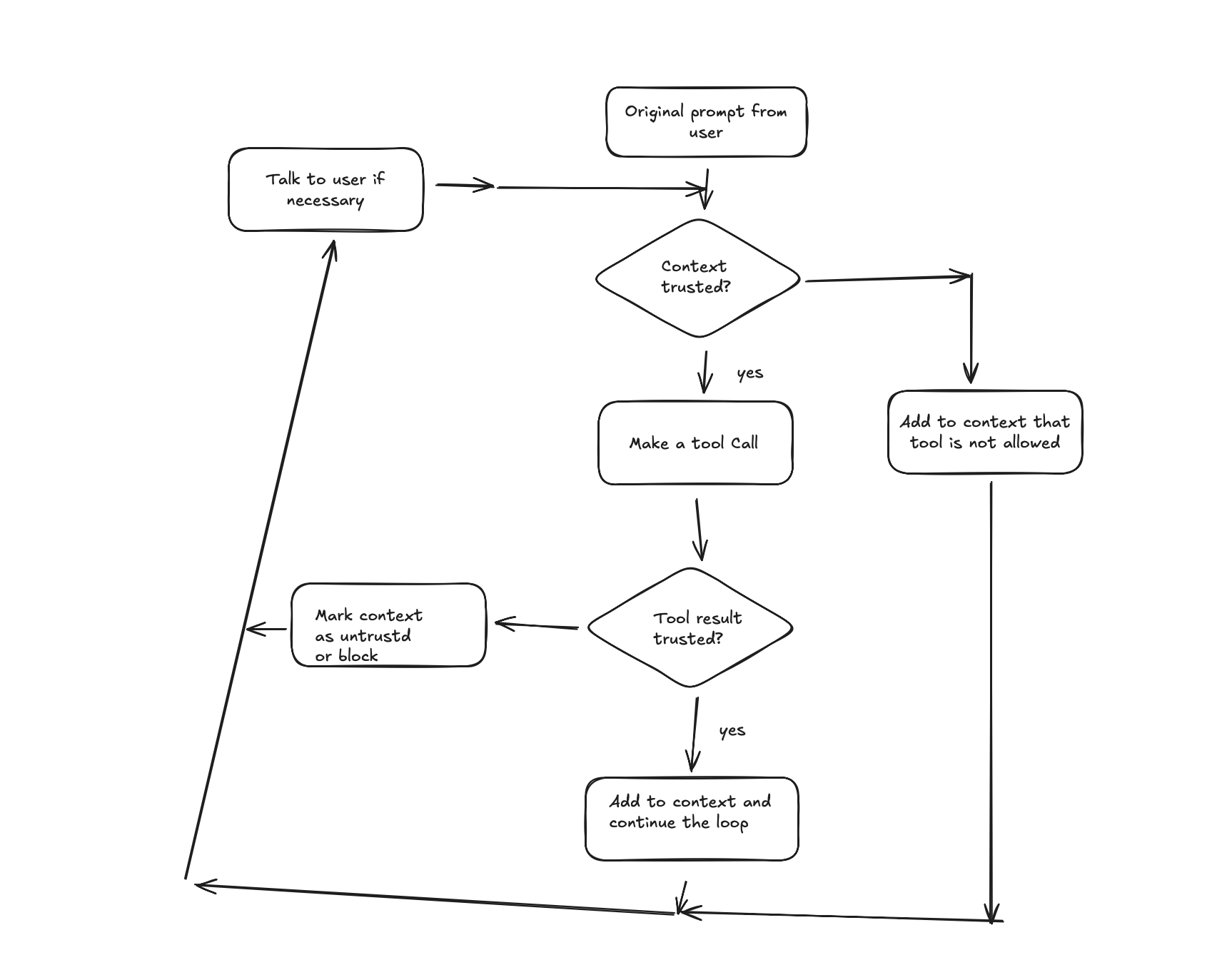
The decision tree for Archestra would be:
All Set
Now you are safe from Lethal Trifecta type attacks and prompt injections cannot influence your agent. With Archestra, the GitHub API response is automatically marked as untrusted, and any subsequent dangerous tool calls (like send_email) are blocked.
To learn more about how Archestra's Dynamic Tools feature works, see the Dynamic Tools documentation.